

Table of Links
3.2 Learning Residual Policies from Online Correction
3.3 An Integrated Deployment Framework and 3.4 Implementation Details
4.2 Quantitative Comparison on Four Assembly Tasks
4.3 Effectiveness in Addressing Different Sim-to-Real Gaps (Q4)
4.4 Scalability with Human Effort (Q5) and 4.5 Intriguing Properties and Emergent Behaviors (Q6)
6 Conclusion and Limitations, Acknowledgments, and References
A. Simulation Training Details
B. Real-World Learning Details
C. Experiment Settings and Evaluation Details
D. Additional Experiment Results
4.4 Scalability with Human Effort (Q5)
Scaling with human effort is a desired property for human-in-the-loop robot learning methods [70]. We show that TRANSIC has better human data scalability than the best baseline IWR in Fig. 6a and Table A.XI. If we increase the size of the correction dataset from 25% to 75% of the full dataset size, TRANSIC achieves a relative improvement of 42% in the average success rate. In contrast, IWR only achieves 23% relative improvement. Additionally, for tasks other than Insert, IWR performance plateaus at an early stage and even starts to decrease as more human data becomes available. We hypothesize that IWR suffers from catastrophic forgetting and struggles to properly model the behavioral modes of humans and trained robots. On the other hand, TRANSIC bypasses these issues by learning gated residual policies only from human correction.
4.5 Intriguing Properties and Emergent Behaviors (Q6)
Finally, we examine further TRANSIC and discuss several emergent capabilities.
Generalization to Unseen Objects We show that a robot trained with TRANSIC can zero-shot generalize to new objects from a novel category. As shown in Fig. 6b, TRANSIC can achieve an average success rate of 75% when zero-shot evaluated on assembling a lamp. However, IWR can only succeed once every three attempts. This evidence suggests that TRANSIC is not overfitted to a particular object, instead, it has learned reusable skills for category-level object generalization.
Effects of Different Gating Mechanisms We introduce the learned gated residual policy in Sec. 3.3 where the gating mechanism controls when to apply residual actions. To assess the quality of learned gating, we compare its performance with an actual human operator performing gating. Results are shown in Table 2. It is evident that the learned gating mechanism only incurs negligible performance drops compared to human gating. This suggests that TRANSIC can reliably operate in a fully autonomous setting once the gating mechanism is learned.
Policy Robustness We investigate the policy robustness against 1) point cloud observations with inferior quality by removing two cameras, and 2) suboptimal correction data with noise injection. See Appendix Sec. C.4 for detailed experiment setups. Results are shown in Table 2. We highlight that TRANSIC is robust to partial point cloud inputs caused by the reduced number of cameras. We attribute this to the heavy point cloud downsampling employed during training. Fishman et al. [91] echos our finding that policies trained with down-sampled synthetic point cloud inputs can
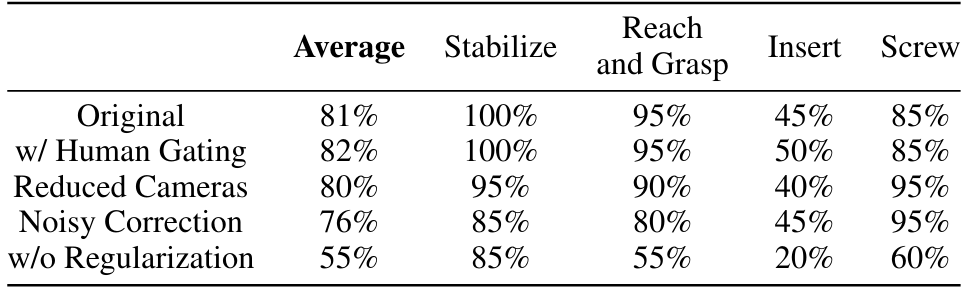
generalize to partial point cloud observations obtained in the real world without the need for shape completion. Meanwhile, when the correction data used to learn residual policies are suboptimal, TRANSIC only shows a relative decrease of 6% in the average success rate. We attribute this to the advantage of our integrated deployment — when the residual policy behaves suboptimally, the base policy could still compensate for the error in subsequent steps.
Importance of Point Cloud Encoder Regularization To learn consistent visual features between the simulation and reality, we propose to regularize the point cloud encoder during the distillation stage as in Eq. 1. As shown in Table 2, the performance significantly decreases without such regularization, especially for tasks that require fine-grained visual features. Without it, simulation policies would overfit to synthetic point cloud observations and hence are not ideal for sim-to-real transfer.
Qualitative Analysis and Emergent Behaviors We first examine the distribution of the collected human correction dataset. During the human-in-the-loop data collection, the probability of intervening and correcting is reasonably low (Pcorrection ≈ 0.20). This is consistent with our intuition that, with a good base policy, interventions are not necessary for most of the time. However, they become critical when the robot tends to behave abnormally due to unaddressed sim-to-real gaps. Moreover, as highlighted in Fig. A.8, interventions happen at different times across tasks. This fact renders heuristics-based methods [92] for deciding when to intervene difficult, and further necessitates our learned residual policy.
Surprisingly, TRANSIC shows several representative behaviors that resemble humans. For instance, they include error recovery, unsticking, safety-aware actions, and failure prevention as shown in Fig. 7.
Solving Long-Horizon Manipulation Tasks Finally, we demonstrate that successful sim-to-real transfer of individual skills can be effectively chained together to enable long-horizon contact-rich manipulation (Fig. 8). See videos on transic-robot.github.io for a robot assembling a square table and a lamp using TRANSIC.
Authors:
(1) Yunfan Jiang, Department of Computer Science;
(2) Chen Wang, Department of Computer Science;
(3) Ruohan Zhang, Department of Computer Science and Institute for Human-Centered AI (HAI);
(4) Jiajun Wu, Department of Computer Science and Institute for Human-Centered AI (HAI);
(5) Li Fei-Fei, Department of Computer Science and Institute for Human-Centered AI (HAI).
This paper is